



5 个用于高级时间序列预测的 Python 库
图片由编辑提供
介绍
预测未来一直是分析的圣杯。无论是优化供应链物流、管理电网负载,还是预测金融市场波动,时间序列预测通常是推动关键决策的引擎。然而,虽然这个概念很简单——使用历史数据来预测未来价值——但执行起来却非常困难。现实世界的数据很少遵循入门教科书中发现的清晰、线性的趋势。
幸运的是,Python 的生态系统已经发展到可以满足这种需求。格局已经从纯粹的统计软件包转变为集成深度学习、机器学习管道和经典计量经济学的丰富库。但面对如此多的选择,选择正确的框架可能会让人不知所措。
本文剔除杂音,重点关注 5 个强大的 Python 库 专为高级时间序列预测而设计。我们超越基础知识,探索能够处理高维数据、复杂季节性和外生变量的工具。对于每个库,我们提供了其突出功能的高级概述和简洁的“Hello World”代码片段,以便您立即熟悉。
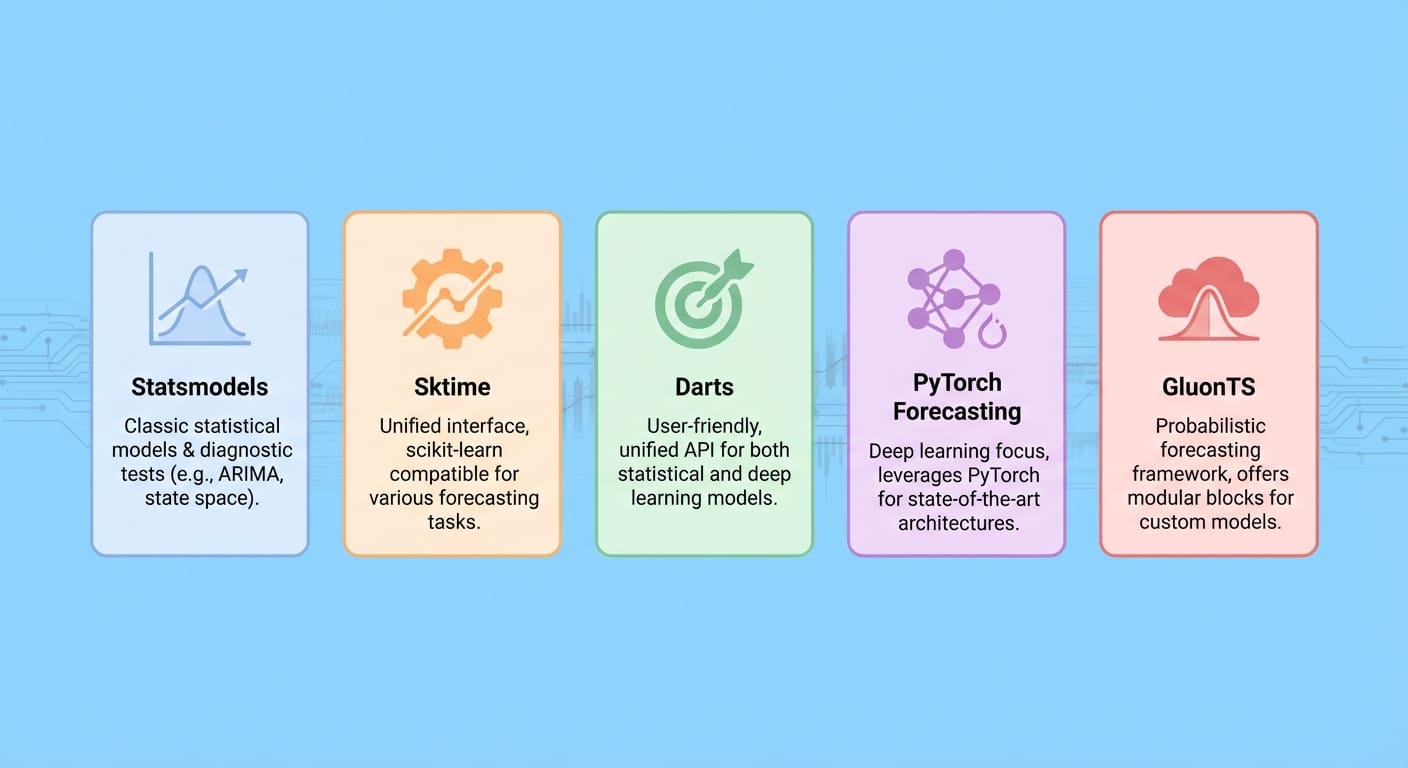
1. 状态模型
国家模型 主要基于统计学和计量经济学的方法,为非平稳和多元时间序列预测提供一流的模型。它还提供对季节性、外生变量和趋势成分的明确控制。
此示例演示如何导入和使用库的 SARIMAX 模型(具有 eXogenous 回归量的季节性自回归综合移动平均线):
|
从 国家模型。察。状态空间。萨里麦克斯 进口 萨利麦克斯 模型 = 萨利麦克斯(y, 外索格=X, 命令=(1,1,1), 季节性订单=(1,1,1,12)) 资源 = 模型。合身() 预报 = 资源。预报(步骤=12, 外索格=X_未来) |
2. 折扣
粉丝 scikit学习?好消息! 小品 模仿流行的机器学习库的风格框架,它适合高级预测任务,通过机器学习模型简化和管道组合实现面板和多元预测。
例如, make_reduction() 函数采用机器学习模型作为基本组件,并应用递归来提前执行多个步骤的预测。注意 fh 是“预测范围”,允许预测 n 步骤,以及 X_future 旨在包含外生属性的未来值(如果模型使用它们)。
|
从 小品。预测。撰写 进口 make_reduction 从 sklearn。合奏 进口 随机森林回归器 预报员 = make_reduction(随机森林回归器(), 战略=“递归”) 预报员。合身(y_train, X_train) y_pred = 预报员。预测(频率=[1,2,3], X=X_未来) |
3. 飞镖
这 飞镖 与其他框架相比,该库因其简单性而脱颖而出。其高级 API 结合了经典模型和深度学习模型来解决概率和多元预测问题。它还有效地捕获过去和未来的协变量。
此示例展示了如何使用 Darts 的 N-BEATS 模型(用于可解释时间序列预测的神经基础扩展分析)实现,这是处理复杂时间模式的准确选择。
|
从 飞镖。型号 进口 NBEATS模型 模型 = NBEATS模型(输入块长度=24, 输出块长度=12, n_epochs=10) 模型。合身(系列, 冗长的=真的) 预报 = 模型。预测(n=12) |
5 个用于高级时间序列预测的 Python 库:简单比较
图片由编辑提供
4.PyTorch 预测
针对海量数据的高维、大规模预测问题, PyTorch 预测 是一个可靠的选择,它结合了最先进的预测模型,如时间融合变压器 (TFT),以及模型可解释性工具。
以下代码片段以简化的方式说明了 TFT 模型的使用。尽管没有明确显示,但该库中的模型通常是从 TimeSeriesDataSet (在示例中, dataset 会扮演这个角色)。
|
从 pytorch_预测 进口 时间融合变压器 薄膜晶体管 = 时间融合变压器。来自数据集(数据集) 薄膜晶体管。合身(火车数据加载器) 前 = 薄膜晶体管。预测(val_dataloader) |
5. 胶子TS
最后, 胶子TS 是一个基于深度学习的库,专门从事概率预测,非常适合处理大型时间序列数据集中的不确定性,包括具有非平稳特征的数据集。
最后我们用一个示例来说明如何导入 GluonTS 模块和类 – 训练用于概率时间序列预测的深度自回归模型 (DeepAR),该模型预测可能的未来值的分布而不是单点预测:
|
从 胶子。模型。深帕 进口 深度ARE估计器 从 胶子。MX。教练员 进口 训练师 估计器 = 深度ARE估计器(频率=“D”, 预测长度=14, 教练员=训练师(纪元=5)) 预测器 = 估计器。火车(训练数据) |
总结
从这个工具库中选择正确的工具取决于您在可解释性、训练速度和数据规模之间的具体权衡。虽然像 Statsmodels 这样的经典库提供了统计的严谨性,但像 Darts 和 GluonTS 这样的现代框架正在突破深度学习利用时态数据所能实现的界限。高级预测中很少有“一刀切”的解决方案,因此我们鼓励您使用这些片段作为启动板,对多种方法进行相互基准测试。尝试不同的架构和外生变量,看看哪个库最能捕捉信号的细微差别。
工具齐备;现在是时候将历史噪音转化为可行的未来见解了。