



2025 年的最后几个月已经成为人工智能世界的一个奇怪的节日。有史以来最强大的三个模型几乎连续出现。开放人工智能 GPT-5.1 位居第一,其次是 Google DeepMind 的 Gemini 3 Pro。最后,Anthropic 的 Claude Opus 4.5 为这个月画上了圆满的句号。
本季这些款式中最引人注目的转变是一个简单的想法。他们不再以直线思考。在较旧的系统中,模型会读取提示并以固定的速度回复响应。在新系统中,当任务需要时,模型会减慢速度。它会遍历一系列想法,检查错误和计划。
思维方式
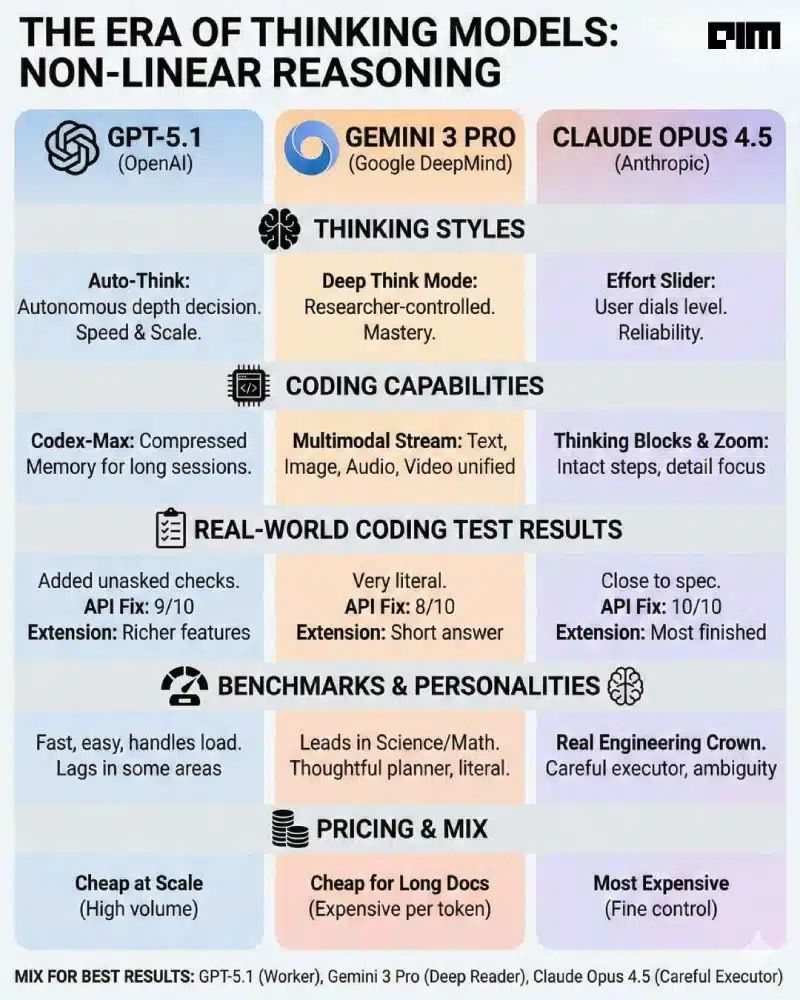
每家公司都针对这种新行为采取了自己的方法。 GPT-5.1 自己决定是深入思考还是加快完成一项简单的任务。没有可供用户翻转的开关。模型读取房间。
双子座 3 专业版 通过深度思考模式提供清晰的选择。研究人员可以打开它来解决复杂的问题。
近距离工作4.5 提供最多的控制。其工作量设置允许用户控制用于任务的令牌数量。这几乎就像调整亮度一样,只不过是为了智能。
这些选择共同为这三个公司如何展望未来定下了基调。 OpenAI 似乎想要速度和规模,Google 想要掌控媒体,而 Anthropic 想要在长时间的复杂任务中保持可靠性。
编码测试
GPT-5.1 还有第二个很重要的技巧。 Codex-Max 是其用于软件工作的专用版本,使用称为压缩的过程。它通过将旧日志和错误转换为压缩内存来保留工作的本质,从而保持长时间的编码会话干净。
这解决了以前系统速度变慢的问题。长循环常常使模型陷入混乱。 Codex-Max 在一整天的调试中保持警惕,而不会丢失上下文。结果不是记忆力变长,而是记忆力更敏锐。
Gemini 3 Pro走了一条不同的路。谷歌构建它是为了将文本、图像、音频和视频视为单个流的一部分。它不会将单独的视觉或音频模块固定在语言核心之上。一切都在统一的空间中处理。
这赋予了它一种不寻常的流动感。它可以理解音频中的语气,掌握长视频中的因果关系,并读取跨越一百万个标记的文档而不将它们分开。
Claude Opus 4.5 试图解决一个更安静但更顽固的问题。在长长的编码或研究链中,较旧的模型常常忘记为什么他们会提前几轮做出选择。 Opus 4.5 从一步到下一步都保持了自己的思维块完整无缺。这可以防止它重复相同的失败想法。
它的行为就像一个清楚地记得以前的尝试的人。它还带来了新鲜的技能。该模型可以以全分辨率放大屏幕的一小部分。它用它来捕捉其他模型错过的文档或界面中的微小细节。
开发商 比较的 GPT-5.1、Gemini 3.0 和 Opus 4.5 跨越三个编码任务,看看它们在实际工作中的表现如何。这个想法很简单。让模型解决相同的问题,观察它们如何处理指令、混乱的遗留代码和不完整的系统。
第一个测试检查了及时的纪律。这些模型必须构建一个具有 10 项严格要求的 Python 速率限制器。双子座以一种非常字面的方式坚持剧本。 Opus 4.5 接近规范并产生更清晰的音符。 GPT-5.1 添加了未请求的检查和安全逻辑。
第二个测试向模型抛出了一个损坏的 TypeScript API,要求他们清理它并修复潜在的设计缺陷。 Opus 4.5 完成了全部 10 项改进。 GPT-5.1 取得了九个成绩,并标记了安全漏洞,例如缺少身份验证和不安全的数据库调用。 Gemini 管理了 8 个并编写了快速代码,但忽略了结构问题。
第三个测试评估了他们在扩展系统之前对系统的理解程度。鉴于通知模块尚未构建完成,模型必须首先解释布局,然后添加电子邮件支持。 Opus 4.5 提供了最完整的答案,并为每个事件提供了模板。
GPT-5.1花了更多的时间阅读系统,指出错误,绘制图表,然后添加更丰富的功能,如抄送、密件抄送和附件。双子座理解了简短的内容,但回答简短。
软件工作显示出截然不同的排名。
Claude Opus 4.5 在实际工程任务中摘得桂冠。在测试实际 GitHub 问题修复的基准测试中,它超越了 GPT-5.1 Codex-Max。两者在这个领域都优于双子座。虽然 Claude 优雅地处理了歧义,但 Codex-Max 却能在最长的会议中幸存下来。双子座在纯粹的算法难题上表现最好,但在混乱的存储库中失去了冷静。
关于基准
这三款车型在基准测试中展现出各自独特的个性。 Gemini 3 Pro 在科学推理方面处于领先地位,对物理、化学和生物学都有很强的掌握。它还在最艰难的新测试“人类最后的考试”中表现最佳。
该分数表明有能力在人类知识仍然不完整且不清楚的领域生成答案。 GPT-5.1 在这一类别中落后,而 Claude Opus 4.5 则介于两者之间。它在科学上有能力,但不占主导地位。
在数学方面,当允许调用外部工具时,双子座就达到了完美。 GPT-5.1 紧随其后。克劳德仍然可靠,但不那么引人注目。惊喜来自于视觉推理。 Gemini 和 Claude 在需要灵活思维的谜题上表现出了敏捷性,而 GPT-5.1 则难以跟上步伐。
底线:定价
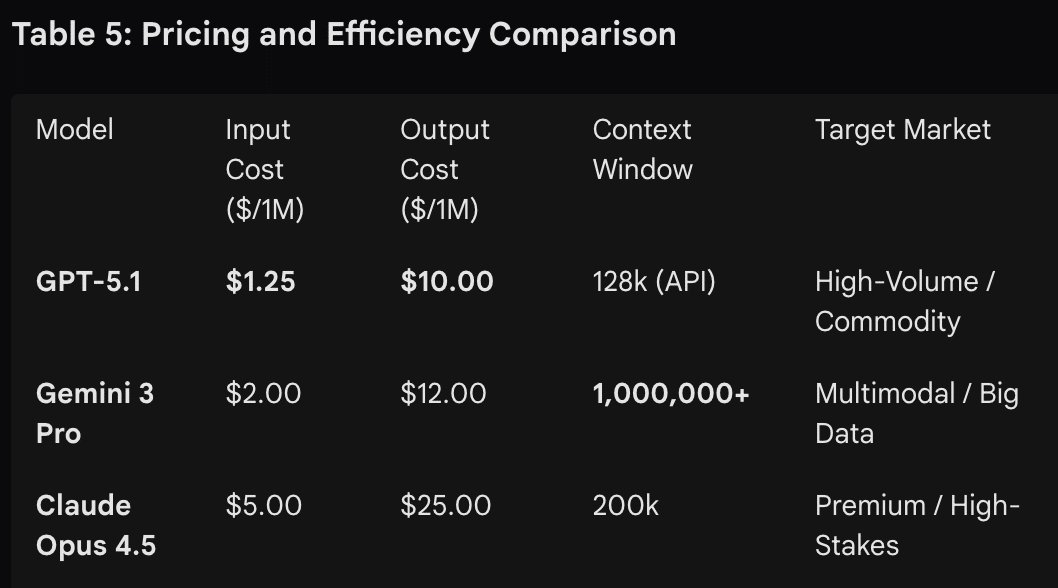
价格再次改变了故事。 OpenAI 已将成本降低到几乎具有战略意义的程度。 GPT-5.1 大规模运行的成本低廉。这使得它非常适合公司和初创公司的大容量工作负载。 Gemini 每个令牌都很昂贵,但由于其巨大的上下文窗口,对于很长的文档来说很有价值。克劳德成本最高,但通过其“努力”设置提供了精细的控制。
围绕这些模型的人类体验带来了自己的色彩。社区论坛上的开发人员例如 Hacker News、Cursor 和 Reddit 描述 Claude Opus 4.5 是一种能够轻松理解意图的产品。它的表现就像一位细心的高级工程师。
双子座给人的感觉是聪明、心思缜密。它擅长规划大型系统,但在执行过程中可能会过于字面意思。
GPT-5.1 被描述为快速且易于使用。它可以快速解决小任务,但有时可以快速解决缓慢的问题。
大多数用户不会选择单一型号。他们将把它们结合起来:GPT-5.1 作为处理负载的可靠工作人员,Gemini 作为深度阅读者,Claude 作为细心的执行者。一种模式统治该领域的想法正在逐渐消失。现在这个领域看起来更像是一项团队运动。