



2024年,NVIDIA凭借先进的GPU在AI供应链领域确立了长期的主导地位。直到 2025 年初 DeepSeek 进入其领域, 具有挑战性的 关于规模的假设并重写人工智能发展的规则。
中国实验室发布了一个推理模型,该模型匹配或超过了多个西方闭源系统,同时仅在 2,048 个 GPU 上训练基本模型 DeepSeek-V2,远少于当时用于获得类似结果的前沿实验室。
资料来源:Andrej Karpathy,前 OpenAI 研究员,2024 年 12 月在 X 上发表的一篇文章。
随着人们的注意力从纯粹的计算转移到架构、训练策略和效率,NVIDIA 的市值在一天之内下跌了 6000 亿美元,这是美国公司跌幅最大的一次,因为投资者重新评估了对更大 GPU 支出的需求。
很快,中国开始在公共服务平台和政府云基础设施上部署 DeepSeek。作为更广泛的人工智能增强教育试点的一部分,大学推出了自动化学习辅助、研究支持、学术规划和 24/7 学生服务的定制实例。甚至医疗保健、汽车制造和军事也集成了 DeepSeek 的法学硕士。
竞争环境促使美国云提供商迎头赶上。
几周之内,AWS 将 DeepSeek-R1 添加到其 AI 服务中。微软将其集成到 Azure AI Foundry 及其模型目录中。 Google 在 Vertex AI 的 Model Garden 中提供了 DeepSeek-R1,使开发人员能够在现有的云工作流程中部署该模型。
去年,DeepSeek 的发展历程被 R1 所定义,其继任者的缺席以及当地竞争对手的接替。
使用模式和市场演变
OpenRouter 是一个统一的 API 网关,可通过单一界面访问数百个 AI 模型,为 DeepSeek 的采用提供了有用的视角。其路由数据集涵盖约 100 万亿个代币,显示 DeepSeek 模型在 2024 年 11 月至 2025 年 11 月期间约占 14.4 万亿个代币。
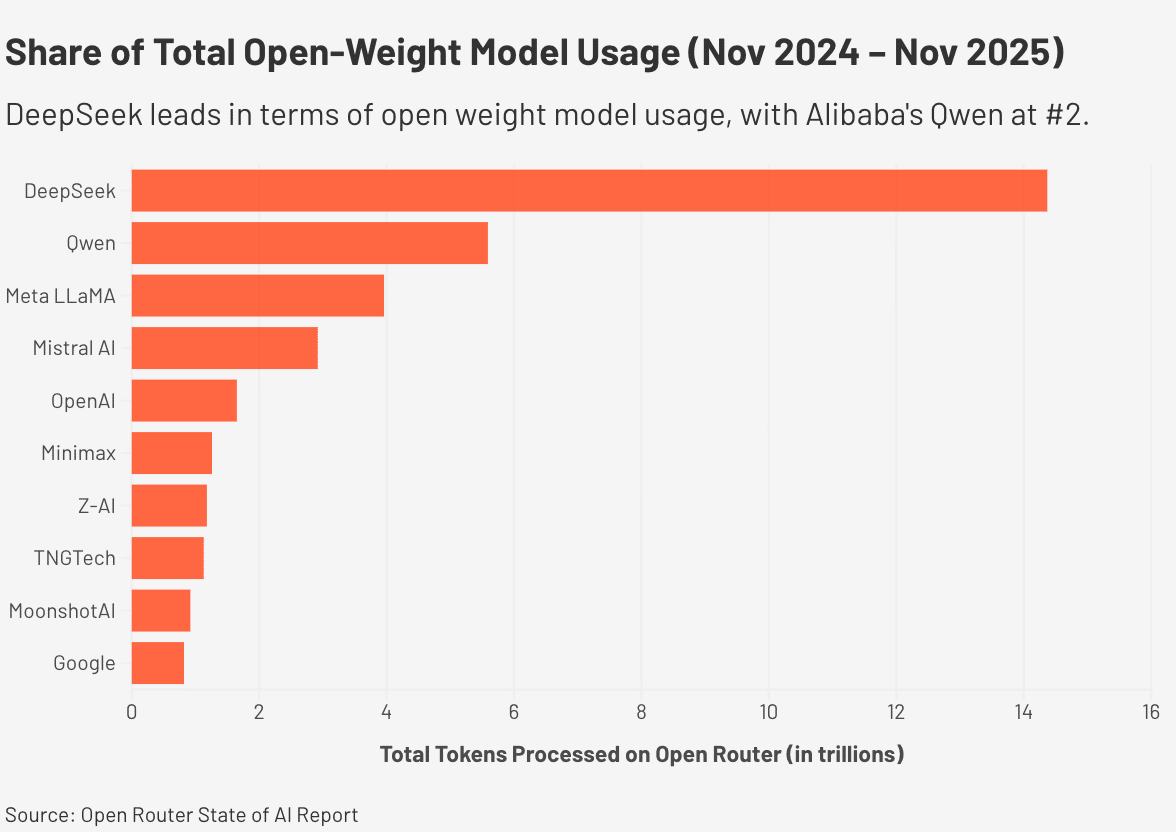
DeepSeek V3和DeepSeek R1发布后,两者合计占该平台所有开源代币流量的一半以上。在此期间,没有其他开放重量模型系列达到了可比的浓度。
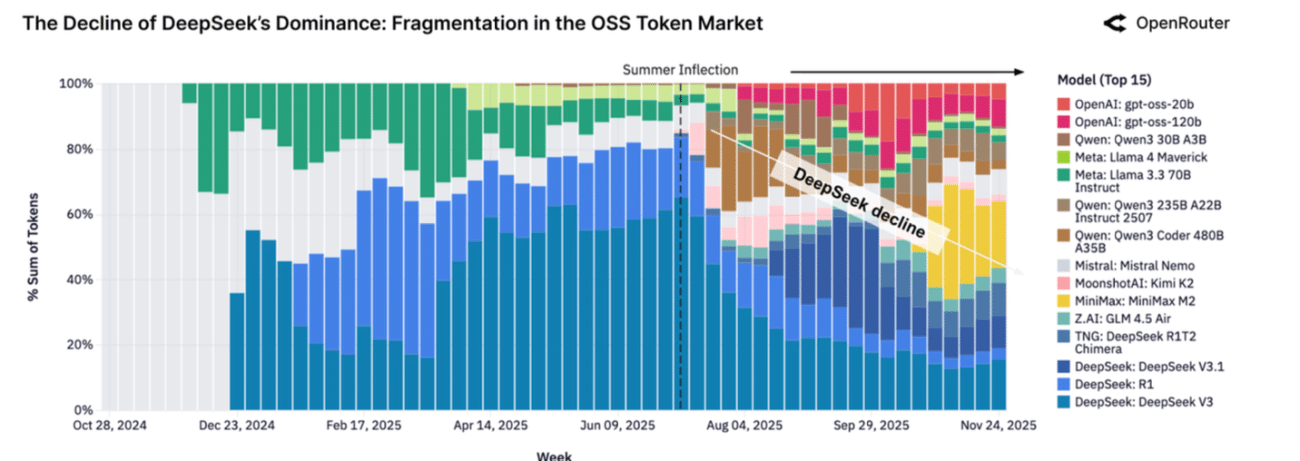
定价在该模型的采用中发挥了重要作用,因为 DeepSeek 始终被列为持续、大容量路由的成本最低的选项之一。但这种主导地位在 2025 年中期左右达到顶峰,然后下降。
OpenRouter 的报告指出了夏季明显的拐点。
来源:OpenRouter
中国开源生态系统并没有出现绝对使用量的崩溃,而是迅速多样化。 Qwen、Moonshot AI (Kimi)、MiniMax 和其他公司的新版本在几周内就捕获了生产流量。
到 2025 年底,没有任何一个开源模型占据了超过 20-25% 的代币份额。 DeepSeek 早期的旗杆位置下降,让位于更加多元化的分布。
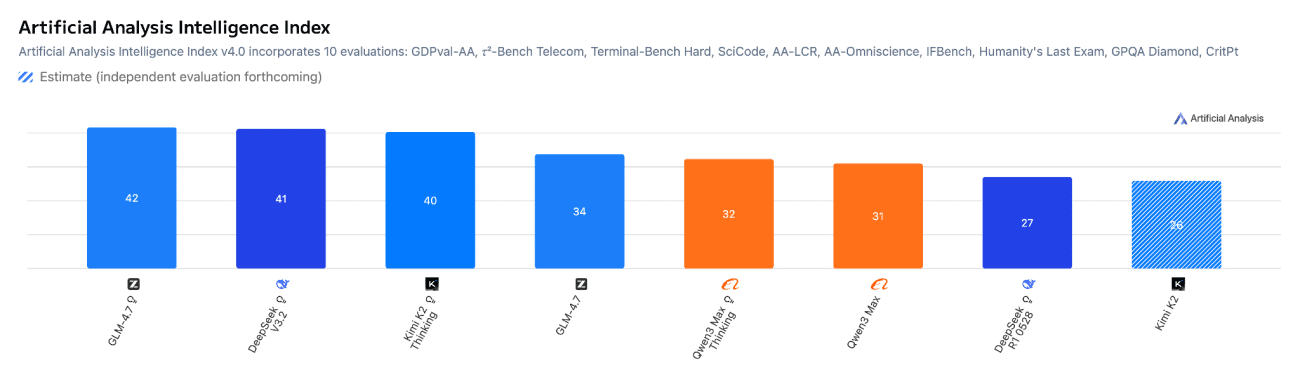
目前,DeepSeek 正在与其他公司正面交锋。 中国人工智能模型 在绝对基准中。但它并不急于夺回王位。
研究重点
DeepSeek 没有像西方人工智能实验室和中国竞争对手那样加速产品发布,而是将重点转向研究、培训方法和基础设施。
R1 之后,DeepSeek 专注于探索 LLM 架构的实质细节,并逐步修复阻碍计算效率的瓶颈。这与该国因美国政府对 NVIDIA 向一家中国科技公司出售 GPU 施加的出口限制而面临的困境是一致的。
2025年2月,通过为期五天的开源计划,DeepSeek发布了专注于执行效率、管道调度、核心计算、并行工作负载协调和大规模存储的框架。这些解决了决定模型是否可以大规模训练和廉价服务的瓶颈,并且直接针对生产工程师。
在这一年中,DeepSeek-R1 还获得了增量更新,提高了其基准性能,并且该公司还在基础模型 DeepSeek-V3 上进行了大量的研究工作和实验。
值得注意的是,9 月份,DeepSeek 释放 V3.2-Exp,一种实验模型,旨在推动长上下文功能,同时保持效率为中心,在 128k 上下文窗口的推理过程中,预填充成本降低 3.5 倍,解码成本降低高达 10 倍。
10月,发布了DeepSeek-OCR。该模型将文本转换为紧凑的视觉标记,实现 9-10 倍的压缩比,精度超过 96%,即使在 20 倍压缩下,精度也约为 60%。这项工作提出了一条新的效率路径,其中视觉模态不用于感知,而是用于语言模型中的记忆和上下文优化。
并且在 11 月发布了 研究 该模型在 2025 年国际数学奥林匹克竞赛中获得了金牌级别的表现,成为继 OpenAI 和 Google DeepMind 之后唯一一家获得金牌的公司。这个模型 DeepSeek-Math-v2 解决了推理和数学基准中日益增长的问题,即许多模型在没有合理或可检查的推理的情况下得出正确的答案。
接下来做什么?
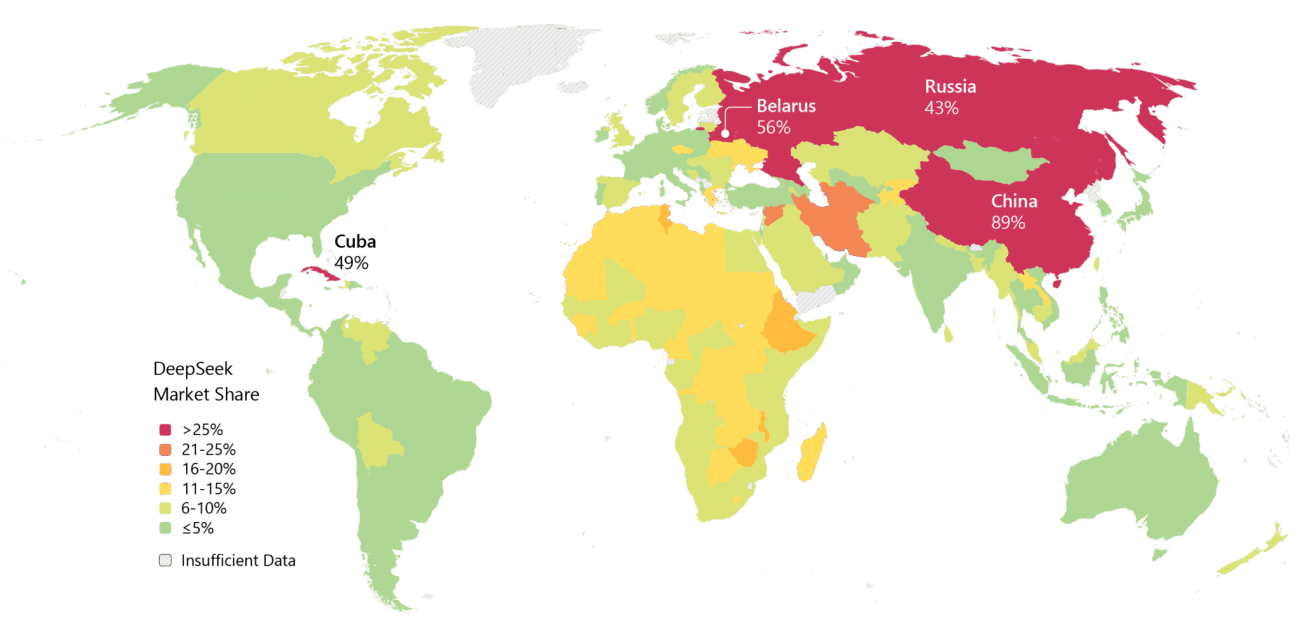
微软最近的一份报告显示 DeepSeek 取得了重大进展 市场渗透率 在中国以外,俄罗斯的使用率约为 43%,白俄罗斯的使用率约为 56%,使其成为全球采用率最高的国家之一。在中国,DeepSeek 在生成式人工智能使用中的份额约为 89%。
来源:微软
相比之下,西欧和北美的采用率仍然很低,通常低于 5%。在许多非洲国家,DeepSeek 的使用量比西欧或北美高出 2-4 倍,这得益于 DeepSeek 的免费或低成本访问以及极小的订阅障碍,这使得它在西方替代品难以获得的价格敏感市场中具有吸引力。
随着增长集中在发展中地区,DeepSeek如何调整其未来的模式和服务以满足这些市场的特定需求将是其全球战略的重要指标。
然而,值得注意的是,R1 车型缺乏继任者。
根据一个 路透社 2025年中期的报告显示,DeepSeek并未在预期时间发布预期的DeepSeek R2,因为包括创始人梁文峰在内的公司领导层对该模型的性能和稳定性不满意,将其推出时间推迟到了原计划的2025年5月日期。
其他因素包括数据标记缓慢、与硬件选择相关的技术问题(例如 DeepSeek 被鼓励采用的华为芯片的不稳定和连接问题),这迫使该公司坚持使用 NVIDIA GPU 进行训练,而仅使用其他芯片进行推理,从而优先考虑稳定性。
据介绍,现在 DeepSeek 计划推出新的基础模型 DeepSeek-v4,明确强调编码和数学性能 信息。但这一次,它在开源生态中将不具备先发优势。
帖子 DeepSeek 的崛起、暂停以及本地竞争如何占据主导地位 首先出现在 分析印度杂志。